Writing Efficient Contracts
Writing functions
On Ethereum L1, all data is public and all execution is completely reproducible. The Aztec L2 takes on the challenge of execution of private functions on private data. This is done client side, along with the generation of corresponding proofs, so that the network can verify the proofs and append any encrypted data/nullifiers (privacy preserving state update).
This highlights a key difference with how public vs private functions are written.
- Public functions can be written intuitively - optimising for execution/gas as one would for EVM L2s
- Private functions are optimised differently, as they are compiled to a circuit to be proven locally (see Thinking in Circuits)
Assessing efficiency
On Aztec (like other L2s) there are several costs/limit to consider...
- L1 costs - execution, blobs, events
- L2 costs - public execution, data, logs
- Local limits - proof generation time, execution
Local Proof generation
Since proof generation is a significant local burden, being mindful of the gate-count of private functions is important. The gate-count is a proportionate indicator of the memory and time required to prove locally, so should not be ignored.
Noir for circuits
An explanation of efficient use of Noir for circuits should be considered for each subsection under writing efficient Noir to avoid hitting local limits. The general theme is to use language features that favour the underlying primitives and representation of a circuit from code.
A couple of examples:
- Since the underlying cryptography uses an equation made of additions and multiplications, these are more efficient (wrt gate count) in Noir than say bit-shifting.
- Unconstrained functions by definition do not constrain their operations/output, so do not contribute to gate count. Using them carefully can bring in some savings, but the results must then be constrained so that proofs are meaningful for your application.
Each optimisation technique has its own tradeoffs and caveats so should be carefully considered with the full details in the linked section.
Overhead of nested Private Calls
When private functions are called, the overhead of a "kernel circuit" is added each time, so be mindful of calling/nesting too many private functions. This may influence the design towards larger private functions rather than conventionally atomic functions.
Profiling using FlameGraph
Measuring the gate count across a private function can be seen at the end of the counter tutorial here. Full profiling and flamegraph commands explained here.
L2 Data costs
Of the L2 costs, the public/private data being updated is most significant. As L2 functions create notes, nullifiers, encrypted logs, all of this get posted into blobs on ethereum and will be quite expensive
L1 Limits
While most zk rollups don't leverage the zero-knowledge property like Aztec, they do leverage the succinctness property. That is, what is stored in an L1 contract is simply a hash.
For data availability, blobs are utilized since data storage is often cheaper here than in contracts. Like other L2s such costs are factored into the L2 fee mechanisms. These limits can be seen and iterated on when a transaction is simulated/estimated.
Examples for private functions (reducing gate count)
After the first section about generating a flamegraph for an Aztec function, each section shows an example of different optimisation techniques.
Inspecting with Flamegraph
You can see the params for the Aztec's flamegraph using: aztec help flamegraph
For example, the resulting flamegraph (as an .svg file) of a counter's increment function can be generated and served with: SERVE=1 aztec flamegraph target/counter-Counter.json increment
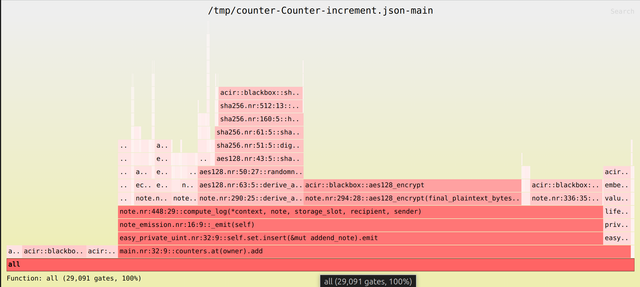
To get a sense of things, here is a table of gate counts for common operations:
| Gates | Operation |
|---|---|
| ~75 | Hashing 3 fields with Poseidon2 |
| 3500 | Reading a value from a tree (public data tree, note hash tree, nullifier tree) |
| 4000 | Reading a shared mutable read |
| X000 | Calculating sha256 |
| X000 | Constrained encryption of a log of Y fields |
| X000 | Constrained encryption and tag a log of Y fields |
Optimization: use arithmetic instead of non-arithmetic operations
Because the underlying equation in the proving backend makes use of multiplication and addition, these operations incur less gates than bit-shifting or bit-masking.
For example:
comptime global TWO_POW_32: Field = 2.pow_32(16);
// ...
{
#[private]
fn mul_inefficient(number: Field) -> u128 {
number as u128 << 16 as u8
} // 5244 gates
#[private]
fn mul_efficient(number: Field) -> u128 {
(number * TWO_POW_32) as u128
} // 5184 gates (60 gates less)
}
When comparing the flamegraph of the two functions, the inefficient shift example has a section of gates not present in the multiplication example. This difference equates to a saving of 60 gates.
In the same vein bitwise AND/OR, and inequality relational operators (>, <) are expensive. Try avoid these in your circuits.
For example, use boolean equality effectively instead of >=:
{
#[private]
fn sum_from_inefficient(from: u32, array: [u32; 1000]) -> u32 {
let mut sum: u32 = 0;
for i in 0..1000 {
if i >= from { // condition based on `>=` each time (higher gate count)
sum += array[i];
}
}
sum
} // 44317 gates
#[private]
fn sum_from_efficient(from: u32, array: [u32; 1000]) -> u32 {
let mut sum: u32 = 0;
let mut do_sum = false;
for i in 0..1000 {
if i == from { // latches boolean at transition (equality comparison)
do_sum = true;
}
if do_sum { // condition based on boolean true (lower gate count)
sum += array[i];
}
}
sum
} // 45068 gates (751 gates less)
}
So for a loop of 1000 iterations, 751 gates were saved by:
- Adding an equivalence check and a boolean assignment
- Replacing
>=with a boolean equivalence check
Such designs with boolean flags lend themselves well into logical comparisons too since && and || do not exist. With booleans, using & and | can give you the required logic efficiently. For more points specific to the Noir language, see this section.
Optimization: Loop design
Since private functions are circuits, their size must be known at compile time, which is equivalent to its execution trace. See this example for how to use loops when dynamic execution lengths (ie variable number of loops) is not possible.
Optimization: considered use of unconstrained functions
Example - calculating square root
Consider the following example of an implementation of the sqrt function:
use dep::aztec::macros::aztec;
#[aztec]
pub contract OptimisationExample {
use dep::aztec::macros::{functions::{initializer, private, public, utility}, storage::storage};
#[storage]
struct Storage<Context> {}
#[public]
#[initializer]
fn constructor() {}
#[private]
fn sqrt_inefficient(number: Field) -> Field {
super::sqrt_constrained(number)
}
#[private]
fn sqrt_efficient(number: Field) -> Field {
// Safety: calculate in unconstrained function, then constrain the result
let x = unsafe { super::sqrt_unconstrained(number) };
assert(x * x == number, "x*x should be number");
x
}
}
fn sqrt_constrained(number: Field) -> Field {
let MAX_LEN = 100;
let mut guess = number;
let mut guess_squared = guess * guess;
for _ in 1..MAX_LEN as u32 + 1 {
// only use square root part of circuit when required, otherwise use alternative part of circuit that does nothing
// Note: both parts of the circuit exist MAX_LEN times in the circuit, regardless of whether the square root part is used or not
if (guess_squared != number) {
guess = (guess + number / guess) / 2;
guess_squared = guess * guess;
}
}
guess
}
unconstrained fn sqrt_unconstrained(number: Field) -> Field {
let mut guess = number;
let mut guess_squared = guess * guess;
while guess_squared != number {
guess = (guess + number / guess) / 2;
guess_squared = guess * guess;
}
guess
}
The two implementations after the contract differ in one being constrained vs unconstrained, as well as the loop implementation (which has other design considerations).
Measuring the two, we find the sqrt_inefficient to require around 1500 extra gates compared to sqrt_efficient.
To see each flamegraph:
SERVE=1 aztec flamegraph target/optimisation_example-OptimisationExample.json sqrt_inefficientSERVE=1 aztec flamegraph target/optimisation_example-OptimisationExample.json sqrt_efficient- (if you make changes to the code, you will need to compile and regenerate the flamegraph, then refresh in your browser to use the latest svg file)
Note: this is largely a factor of the loop size choice based on the maximum size of number you are required to be calculating the square root of. For larger numbers, the loop would have to be much larger, so perform in an unconstrained way (then constraining the result) is much more efficient.
Example - sorting an array
Like with sqrt, we have the inefficient function that does the sort with constrained operations, and the efficient function that uses the unconstrained sort function then constrains the result.
//...
{
#[private]
fn sort_inefficient(array: [u32; super::ARRAY_SIZE]) -> [u32; super::ARRAY_SIZE] {
let mut sorted_array = array;
for i in 0..super::ARRAY_SIZE as u32 {
for j in 0..super::ARRAY_SIZE as u32 {
if sorted_array[i] < sorted_array[j] {
let temp = sorted_array[i as u32];
sorted_array[i as u32] = sorted_array[j as u32];
sorted_array[j as u32] = temp;
}
}
}
sorted_array
} // 6823 gates for 10 elements, 127780 gates for 100 elements
#[private]
fn sort_efficient(array: [u32; super::ARRAY_SIZE]) -> [u32; super::ARRAY_SIZE] {
// Safety: calculate in unconstrained function, then constrain the result
let sorted_array = unsafe { super::sort_array(array) };
// constrain that sorted_array elements are sorted
for i in 0..super::ARRAY_SIZE as u32 {
assert(sorted_array[i] <= sorted_array[i + 1], "array should be sorted");
}
sorted_array
} // 5870 gates (953 gates less) for 10 elements, 12582 gates for 100 elements (115198 gates less)
}
unconstrained fn sort_array(array: [u32; ARRAY_SIZE]) -> [u32; ARRAY_SIZE] {
let mut sorted_array = array;
for i in 0..ARRAY_SIZE as u32 {
for j in 0..ARRAY_SIZE as u32 {
if sorted_array[i] < sorted_array[j] {
let temp = sorted_array[i as u32];
sorted_array[i as u32] = sorted_array[j as u32];
sorted_array[j as u32] = temp;
}
}
}
sorted_array
}
Like before, the flamegraph command can be used to present the gate counts of the private functions, highlighting that 953 gates could be saved.
Note: The stdlib provides a highly optimised version of sort on arrays, array.sort(), which saves even more gates.
#[private]
fn sort_stdlib(array: [u32; super::ARRAY_SIZE]) -> [u32; super::ARRAY_SIZE] {
array.sort();
} // 5943 gates (880 gates less) for 10 elements, 13308 gates for 100 elements (114472 gates less)
Example - refactoring arrays
In the same vein, refactoring is inefficient when done constrained, and more efficient to do unconstrained then constrain the output.
{
#[private]
fn refactor_inefficient(array: [u32; super::ARRAY_SIZE]) -> [u32; super::ARRAY_SIZE] {
let mut compacted_array = [0; super::ARRAY_SIZE];
let mut index = 0;
for i in 0..super::ARRAY_SIZE as u32 {
if (array[i] != 0) {
compacted_array[index] = array[i];
index += 1;
}
}
compacted_array
} // 6570 gates for 10 elements, 93071 gates for 100 elements
#[private]
fn refactor_efficient(array: [u32; super::ARRAY_SIZE]) -> [u32; super::ARRAY_SIZE] {
let compacted_array = unsafe { super::refactor_array(array) };
// count non-zero elements in array
let mut count = 0;
for i in 0..super::ARRAY_SIZE as u32 {
if (array[i] != 0) {
count += 1;
}
}
// count non-zero elements in compacted_array
let mut count_compacted = 0;
for i in 0..super::ARRAY_SIZE as u32 {
if (compacted_array[i] != 0) {
count_compacted += 1;
} else {
assert(compacted_array[i] == 0, "trailing compacted_array elements should be 0");
}
}
assert(count == count_compacted, "count should be equal to count_compacted");
compacted_array
} // 5825 gates (745 gates less), 12290 gates for 100 elements (80781 gates less)
}
unconstrained fn refactor_array(array: [u32; ARRAY_SIZE]) -> [u32; ARRAY_SIZE] {
let mut compacted_array = [0; ARRAY_SIZE];
let mut index = 0;
for i in 0..ARRAY_SIZE as u32 {
if (array[i] != 0) {
compacted_array[index] = array[i];
index += 1;
}
}
compacted_array
}
Optimizing: Reducing L2 reads
If a struct has many fields to be read, we can design an extra variable maintained as the hash of all values within it (like a checksum). When it comes to reading, we can now do an unconstrained read (incurring no read requests), and then check the hash of the result against that stored for the struct. This final check is thus only one read request rather than one per variable.
When needing to make use of large private operations (eg private execution or many read requests), use of unconstrained functions wisely to reduce the gate count of private functions.